Data on a Row vs Columnar Data Store
I always use to wonder about this question, especially the difference between row store databases and columnar databases. In this blog, I will talk a little bit about how data is stored in row store databases such as MySQL and Postgresql. This is really important to understand because it helps us understand and optimize our DB performance. This also becomes very important when writing database queries from your application. An inefficient database query will bog down the overall performance of the database and hence the application.
But before that, we need to discuss a few core database storage concepts.
ROWID pseudocolumn
The ROWID is a unique column, much like a primary key, that is generated internally by the system and returns the address of a row. Unlike a primary key which is maintained by the user to refer row inside a table, ROWID is created and hidden from the user.
| Row_Id (Hidden) | User_id (primary key) | Name | Order | Amount |
|---|---|---|---|---|
| 1 | 00001 | Alex | 789654 | 100 |
| 2 | 00002 | Tom | 789655 | 59 |
Page
In a row-based database, a set of rows is stored together on the disk, these set of rows are known as pages. These pages are fixed-size units and can be configured to optimize a database, for example, PostgreSQL’s default page size is 8KB.
When we try to read a single row, let’s say using SELECT, it will read the entire page and will filter the row we selected. For example, if a single page store 100 rows, running a query to read a single row would return 100 rows against each operation. On the other hand, if you reduce the size of the page, and you want to select multiple sequential rows this will increase the IO operations on the disk and hence slow down the database.
Index
Indexes are used to find rows with specific column values quickly. Without an index, a database must begin with the first row and then read through the entire table to find the relevant rows. An index can pinpoint the page where the row you are looking for is stored. An index is also stored as a page on the disk, so we have to be careful in selecting the column we want to index because we can not index everything.
Row Store vs Column Store
As explained earlier, row store databases are stores all rows (in most cases) together these rows are placed in chucks together called pages. Unlike in a row store, columnar databases stores entire columns together if the column does not fit on a single page it will break the column into multiple pages.
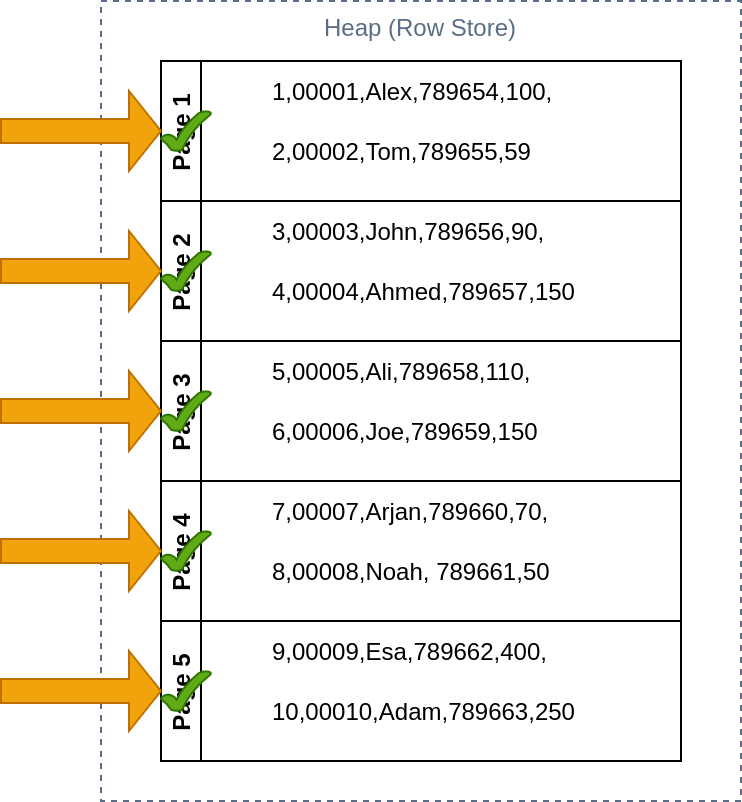
Let me explain with an example, let’s say that we have a table shown below. We also assume that a page can only store 2 rows.
| Row_Id (Hidden) | User_id (primary key) | Name | Order | Amount |
|---|---|---|---|---|
| 1 | 00001 | Alex | 789654 | 100 |
| 2 | 00002 | Tom | 789655 | 59 |
| 3 | 00003 | John | 789656 | 90 |
| 4 | 00004 | Ahmed | 789657 | 150 |
| 5 | 00005 | Ali | 789658 | 110 |
| 6 | 00006 | Joe | 789659 | 150 |
| 7 | 00007 | Arjan | 789660 | 70 |
| 8 | 00008 | Noah | 789661 | 50 |
| 9 | 00009 | Esa | 789662 | 400 |
| 10 | 00010 | Adam | 789663 | 250 |
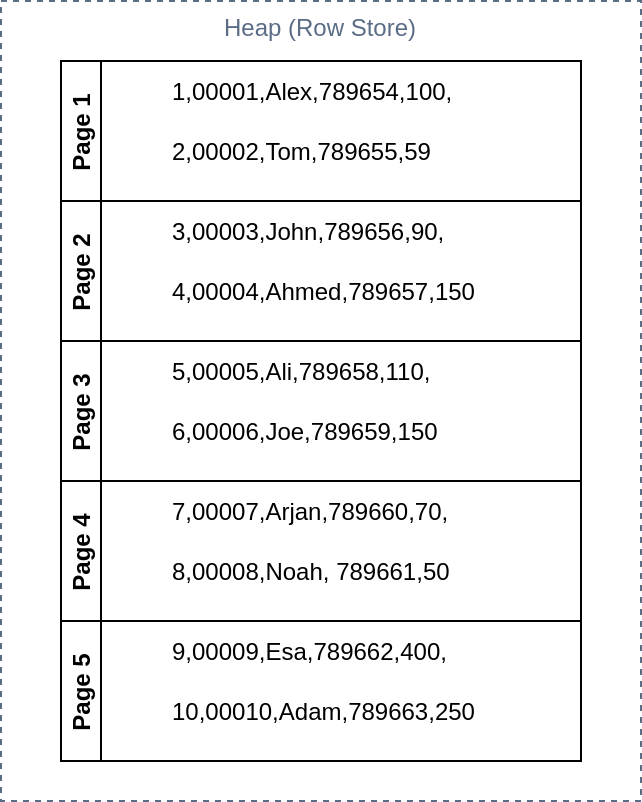
With these assumption a row-oriented database on the disk will look something like this.
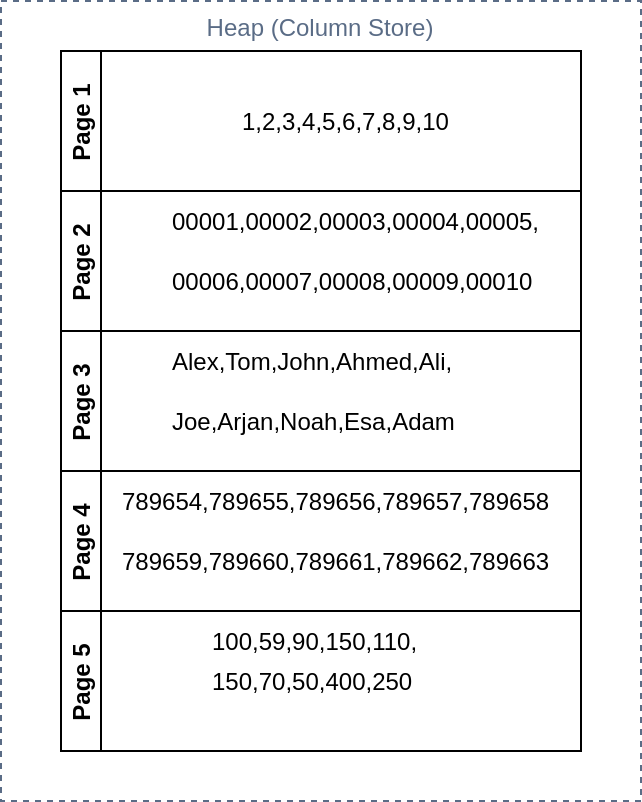
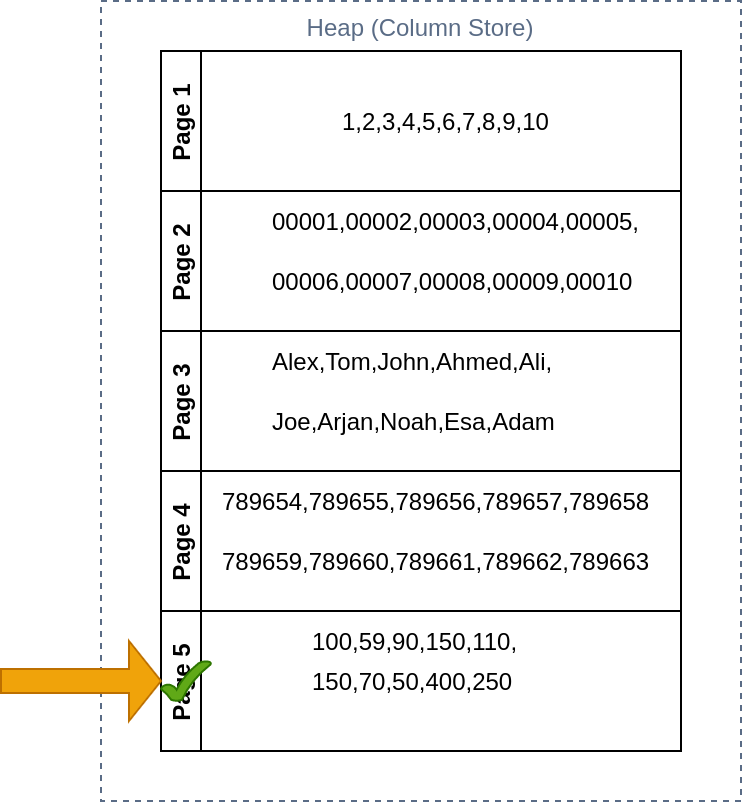
On a column-oriented database, the data will be stored as shown below.
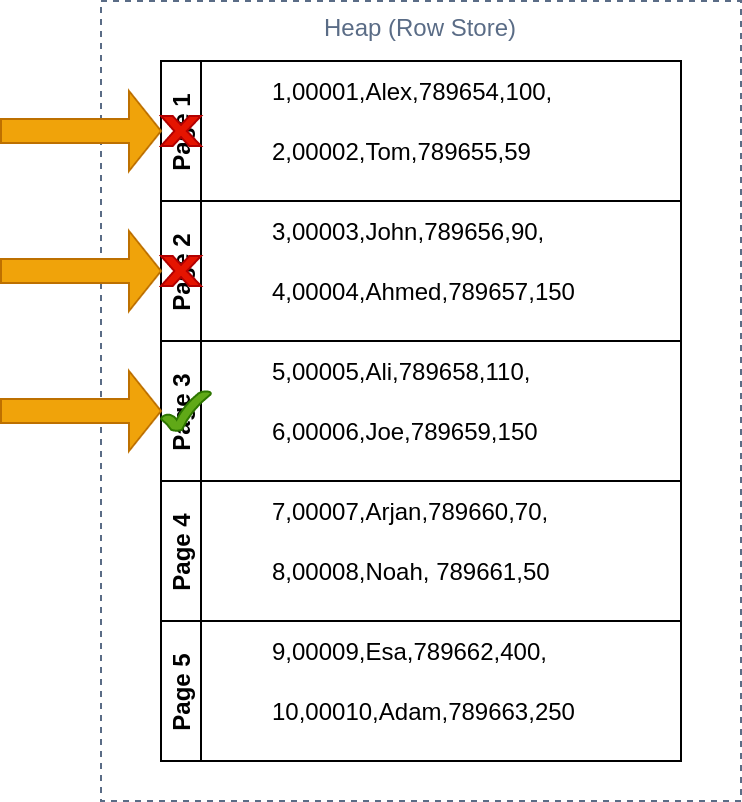
Now imagine that you want to run a query to select all the columns of a row, for example,
SELECT * FROM Table WHERE User_id = 00005;
On a row-oriented database, if there was no indexing, the database engine will go page by page, until it finds the page where the row is located. The database will load both the rows on that page and filter the row that was required.
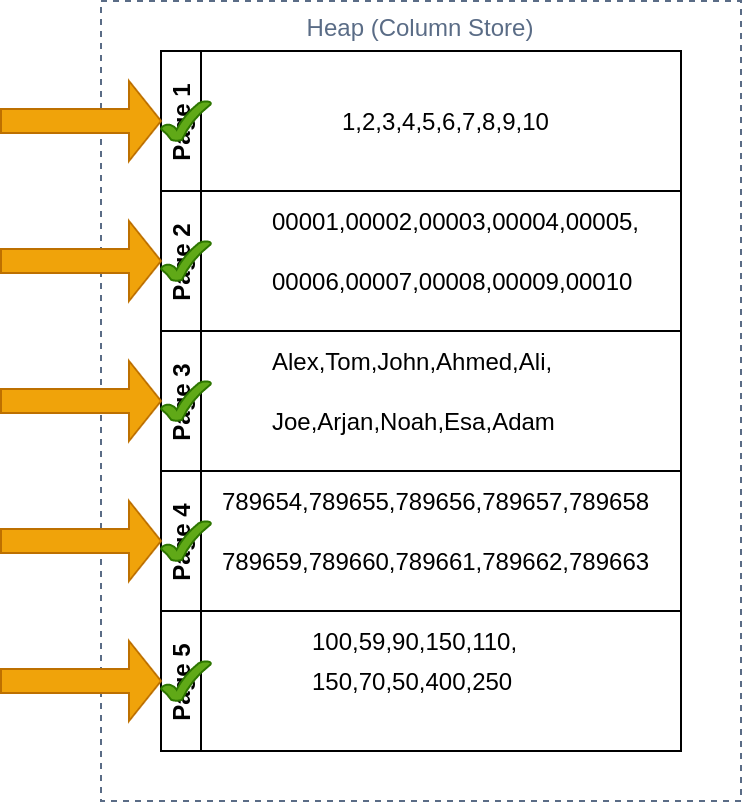
If we run the same query on a columnar database, the database will have to load every page in the memory from the disk and start filtering the data that is required. This will the same case if we were to update an entry. As you can imagen these types of queries are not very efficient on a columnar database.
Now let’s try a different kind of query, let’s say you need to pull the ‘Amount’ column.
SELECT Amount FROM Table;
On a row database, we will have to go through every page and filter out the column.
On a columnar database, this query will be very efficient as all the data we need is written on a single page.
I hope that this little explanation tells you what is the difference between columnar vs row databases and why we should go for column-oriented databases for analytic processing.